98%+ annotation accuracy · All data types
Data Annotation Services
Your ML models need training data labeled accurately at scale, but your engineering team can’t keep up. Acelerar’s trained annotators handle image, text, audio, and video annotation with 98%+ accuracy and multi-tier QA, so your models train on reliable data from day one.





Data Annotation
What are data annotation services?
Data annotation is the process of labeling raw data - images, text, audio, and video - with structured tags that machine learning models use for training. Without accurately annotated data, supervised learning models cannot learn to classify, detect, or predict. Annotation types include bounding boxes for object detection, polygon segmentation for pixel-level precision, named entity recognition for text, sentiment labeling, audio transcription with speaker diarization, and video frame-by-frame tracking. The challenge is not just labeling data, but labeling it consistently at scale with quality controls that prevent noisy training sets from degrading model performance.
Market Data
The data management outsourcing market
Data management outsourcing is growing as businesses deal with increasing data volumes.
Annotation Types
Every annotation type your ML pipeline needs
Image & video annotation
Bounding boxes, polygon segmentation, polyline annotation, keypoint detection, and semantic segmentation for computer vision models. We handle everything from simple 2D object detection labels to complex 3D point cloud annotation for autonomous driving datasets. Our annotators are trained on specific object taxonomies and follow your labeling guidelines with inter-annotator agreement rates above 95%.
See data labeling services →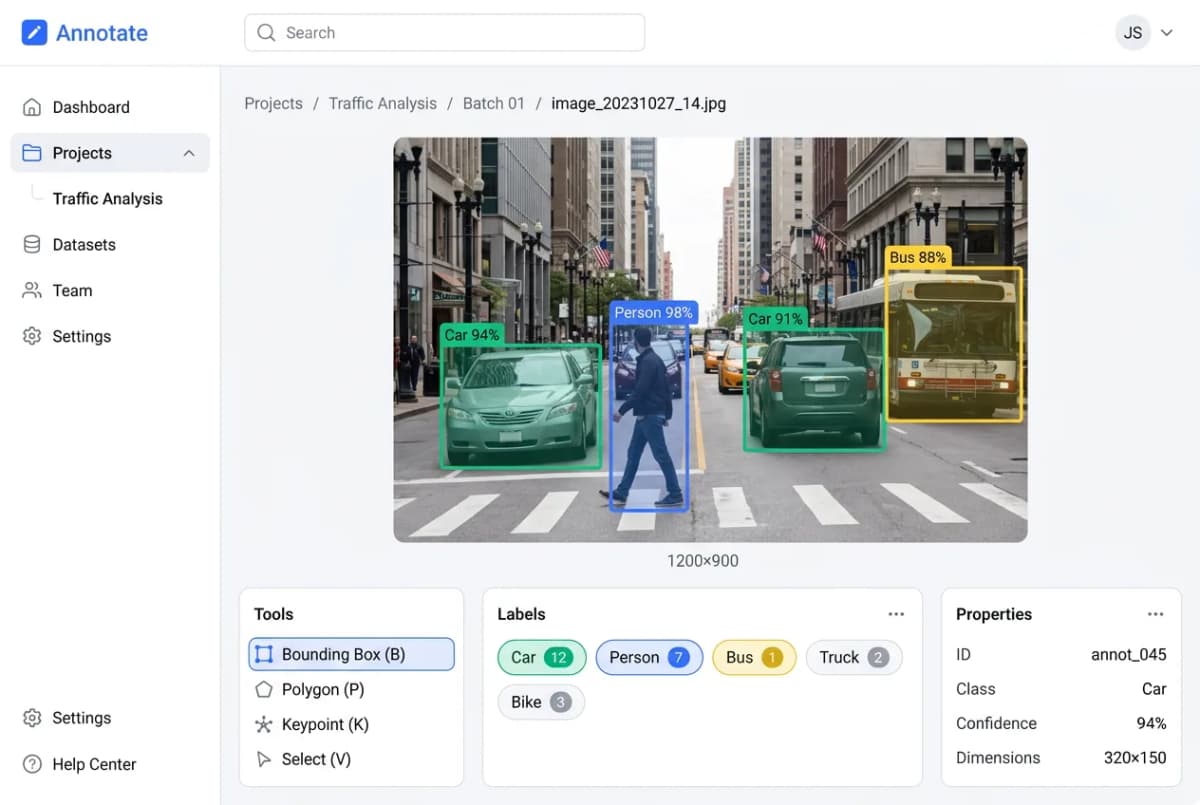
Text & NLP annotation
Named entity recognition, sentiment analysis, intent classification, part-of-speech tagging, text summarization, and relation extraction. We annotate in 15+ languages for multilingual NLP models. Our text annotation teams are domain-trained for medical, legal, financial, and technical content where terminology matters for accurate labeling.
See data management services →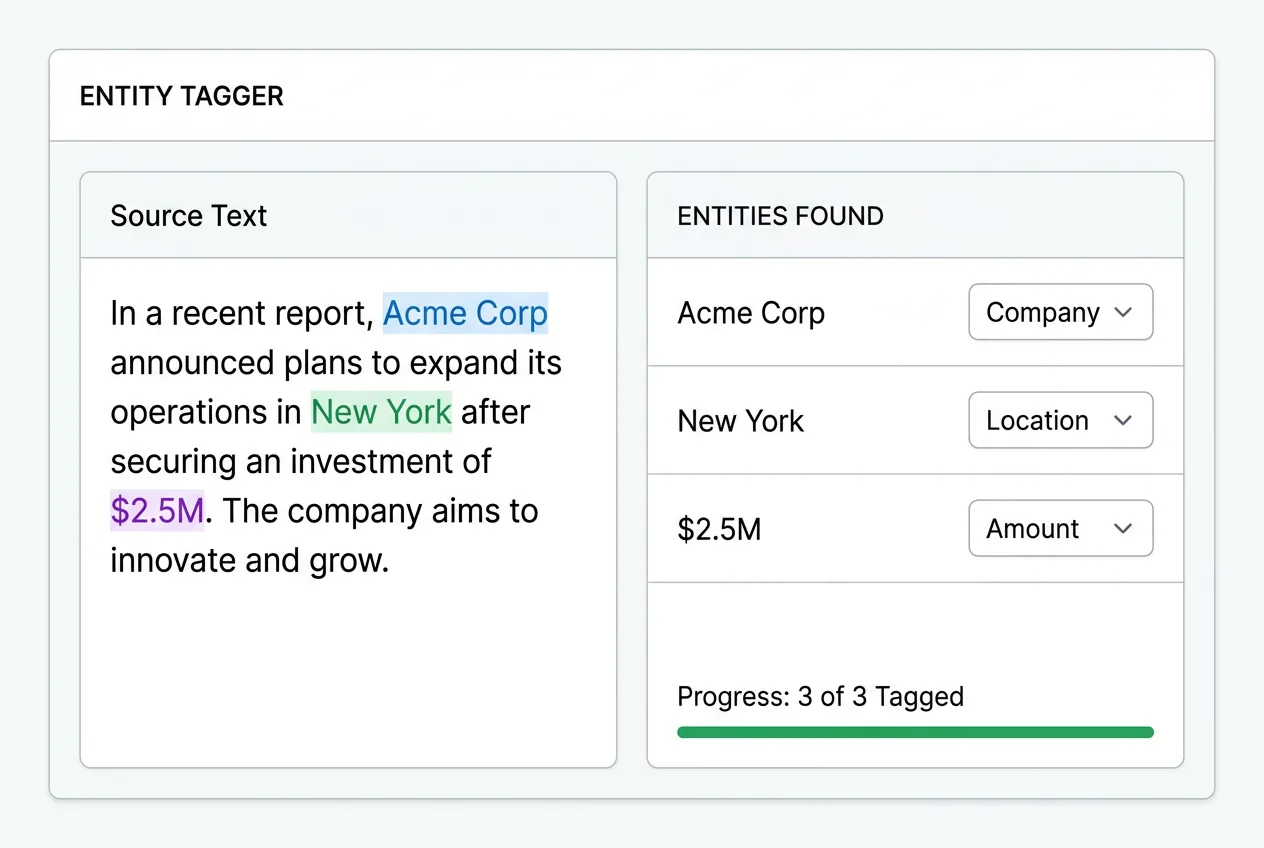
Audio & speech annotation
Audio transcription, speaker diarization, emotion detection, sound event classification, and phonetic annotation. We process conversational AI training data, voice assistant datasets, and call center recordings with timestamp-level precision. Multi-speaker scenarios and noisy audio environments are handled by annotators trained in acoustic labeling protocols.
See data labeling services →
Cost Savings
The real cost of in-house data annotation
A full-time data annotator in the US costs $38,000 to $48,000/year with benefits. With Acelerar, you get trained annotation teams for a fraction, and scale with your ML pipeline.
$42K/yr
per year / per person
Salary · Benefits · Annotation tools · QA reviews
$13K/yr
per year / per person
Guideline-calibrated · Multi-format · 95%+ agreement
Why Outsource Data Annotation
Why ML teams outsource annotation to Acelerar
98%+ Annotation Accuracy
Multi-tier QA process: annotator self-review, peer review on 20% of samples, and senior reviewer spot-checks. Inter-annotator agreement measured and reported for every batch.
Trained Domain Annotators
Our annotators are trained on your specific taxonomy, labeling guidelines, and edge case protocols before the first label is placed. No generic crowdsourcing - dedicated teams that learn your domain.
Scale to Millions of Labels
From 1,000 images to 1,000,000+. Our team capacity scales within days, not weeks. Maintain consistent quality at 10x volume because trained annotators follow the same guidelines at every scale.
All Annotation Types Covered
Bounding box, polygon, polyline, keypoint, semantic segmentation, NER, sentiment, intent, audio transcription, speaker diarization - one vendor for every annotation need in your pipeline.
70% Cost Savings vs. US Annotators
US-based annotation teams cost $25-$40/hour per annotator. Acelerar delivers the same quality at 70% less, freeing budget for more training data and faster model iteration cycles.
Platform Agnostic
We work within your preferred annotation tool - Labelbox, CVAT, Prodigy, Label Studio, V7, Scale, or custom platforms. No tool migration required. We adapt to your workflow, not the other way around.
How It Works
From raw data to ML-ready annotations in 5 steps
Define
We review your annotation guidelines, taxonomy, and edge cases. Unclear instructions are clarified before labeling begins to prevent rework.
Calibrate
Annotators complete a pilot batch (100-500 samples). You review, provide feedback, and we calibrate until the output matches your expectations.
Annotate
Full-scale annotation begins with trained, dedicated annotators following your guidelines. Daily output tracked and quality metrics reported.
Review
Multi-tier QA: self-review, peer review on 20% of samples, and senior reviewer validation. Inter-annotator agreement scores calculated per batch.
Deliver
Annotated data exported in your required format (COCO, Pascal VOC, YOLO, custom JSON) with quality report and annotation statistics.
ML pipeline bottlenecked by annotation?
Send us your annotation guidelines and a sample dataset. We’ll return a pilot batch within 5 days so you can evaluate quality before committing.
Start a Pilot ProjectWe work with your data platforms
Our teams are trained on the platforms you already use.
What our data management clients say
“The Acelerar team is a self-sustaining machine. They’ve become an extension of our own team.”
“We needed reliable, fast data entry at scale. Acelerar delivered consistent quality from day one, no ramp-up time needed.”
“Acelerar handled our entire catalog migration (50,000+ SKUs) without a single missed deadline.”
Industry Outlook
Where data management outsourcing is heading
Data volumes are exploding, and outsourced data management teams are evolving with AI capabilities.